

.png)
.svg)
We have developed an application that can be asked how a product group's margin has developed over the last 12 months, and in response, it provides an accurate description of the development and the reasons that affected the change. Solutions of this type are already commonplace, but what does the production deployment of such an application practically mean in a large company?

It is no longer debated anywhere whether a company will adopt AI or large language models. The bigger question is whether the organization's data is in good enough condition, accessible, and the metadata is in such a state that AI can genuinely be beneficial.
My intention is to use my own experiences to explain how to approach metadata, not so much as a philosophical exercise but as a practical matter. The goal is, after all, to be able to talk with data.
What is good to know before the conversation?
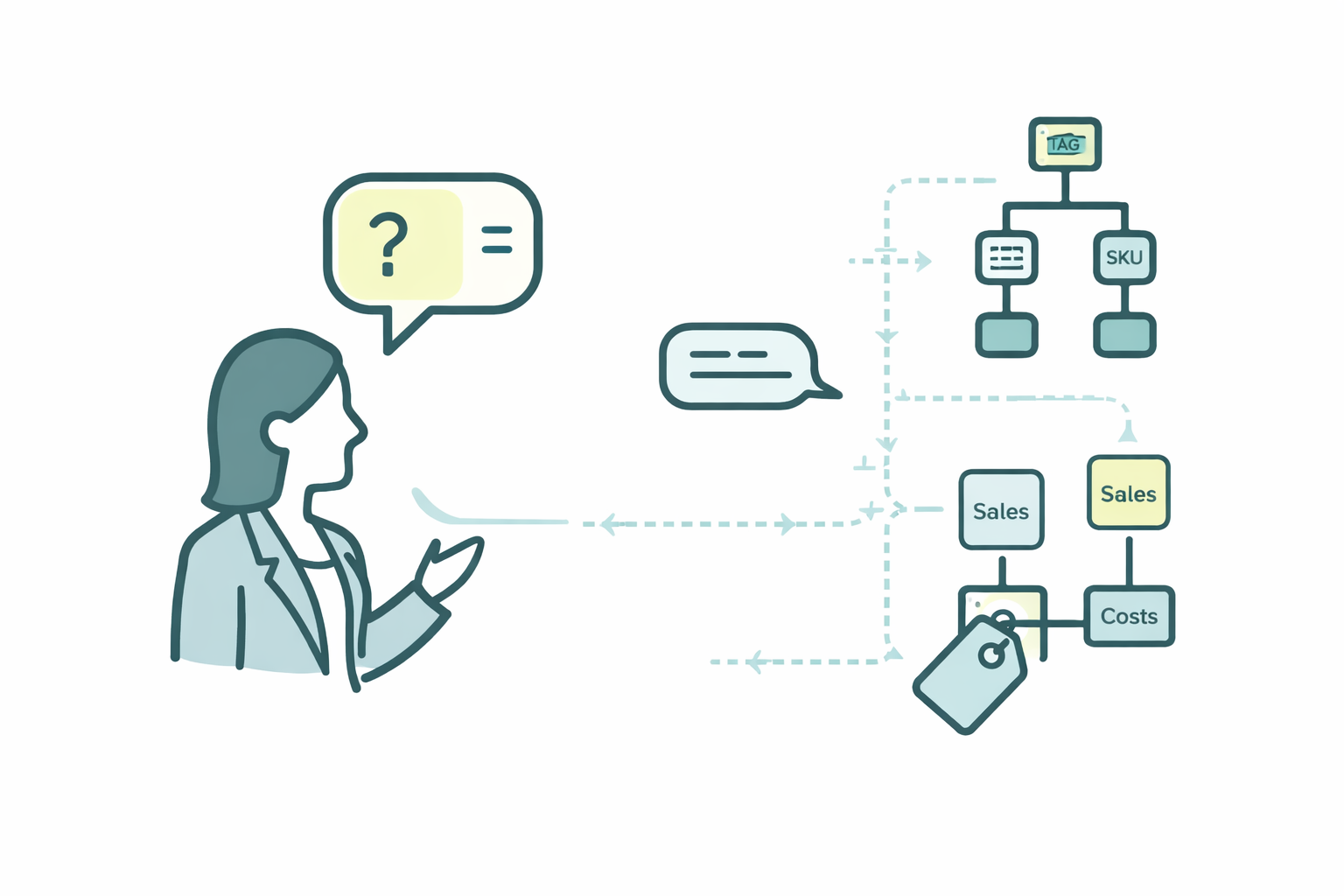
Metadata is information about information. A large language model fills in gaps in its knowledge, and the filled gap sounds reliable. A large language model does not admit to guessing. If a data field is named marg_adj_3 and its meaning is not documented, the language model tries to guess from other context. In a large environment, this approach leads to answers that sound correct but are not necessarily so.
A good application architecture can mitigate this problem, for example, by forcing the model to state when it does not know the answer. But architecture alone is not enough. Reliable metadata and the correct architecture together make the answer reliable.
Another practical problem is that the same thing means different things in different parts of the organization. In the context of an industrial company, "margin" can mean gross margin, operating margin, or contribution margin, depending on who is asked. Without common terminology, the application cannot provide the correct context to the language model, which can lead to the answer being based on incorrect data.
By defining and documenting concepts, the language model can connect the user's natural language to the correct data and justify its answers using the business's own language. Then talking with data becomes meaningful.
What should metadata include?
A conceptual model is a good place to start. It has been done before. We determine what the key concepts are and how they describe the company's operations. Customer, product, supplier. What business concepts does the organization have? Product group, margin, sales organization, sales channel. These form the core of the business glossary. Language models are a truly excellent working partner in this task.
The next step is the relationships between the concepts. A product group belongs to a product hierarchy, margin is calculated from sales and costs, and costs have their own classification. A product is associated with an item and various properties. Ontology makes the relationships between concepts concrete, allowing the language model to understand the structure of the information, so it doesn't have to deduce it from the names or context of individual fields.
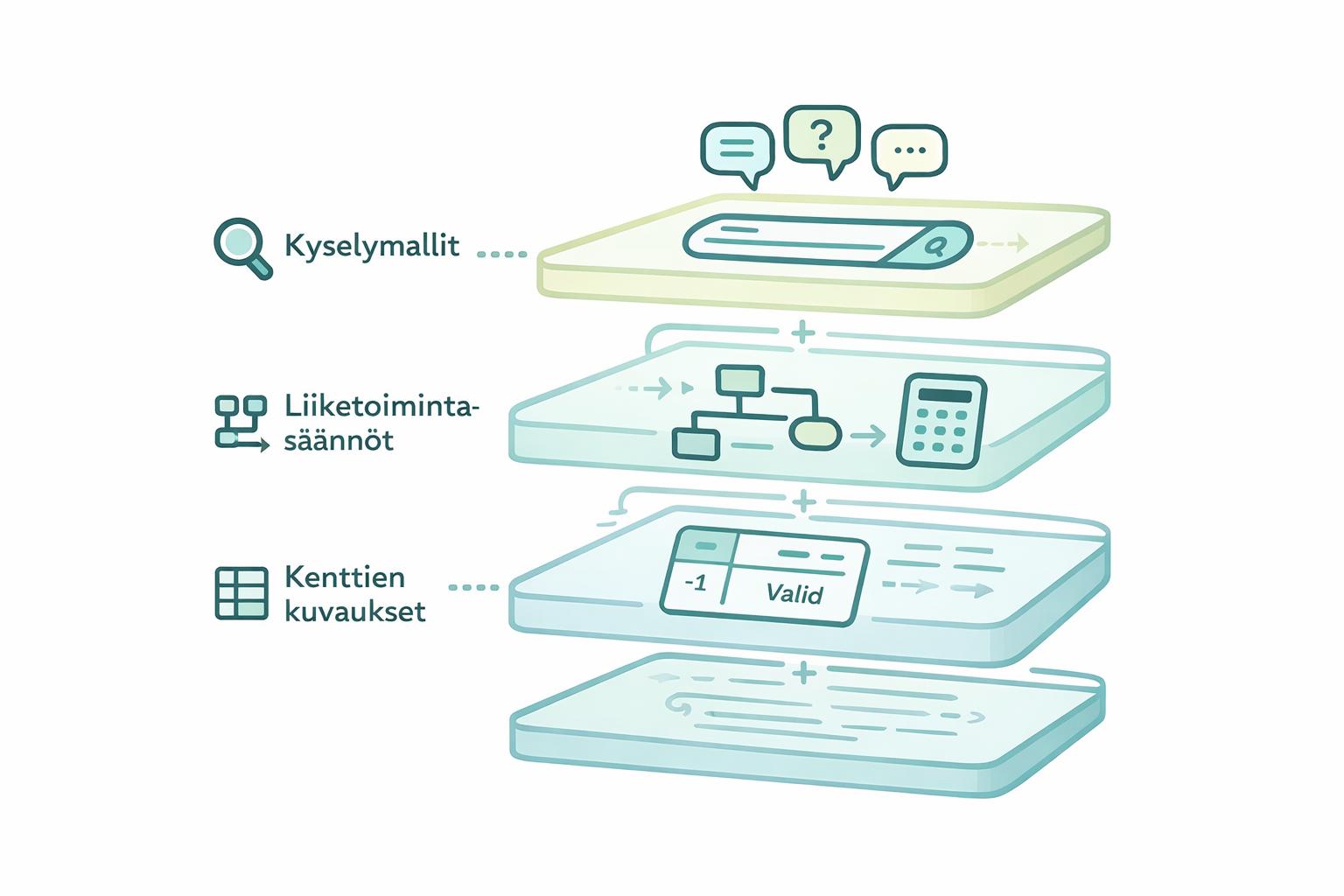
Once a semantic model exists, the application knows how to fetch the correct data definitions and make them available to the language model.
In practice, however, a semantic model is not a single file or document. It consists of several layers with different tasks:
Descriptions of columns and fields tell the language model what each data field means and what values are allowed. For example, in real estate data, the value -1 might mean "all categories combined". Without this information, the language model might treat it as an erroneous number.
Query models link typical questions to the correct search methods. When a user asks "how have rents developed," the system recognizes this as a time series query and knows how to retrieve the correct data in the right way.
Business rules define how concepts relate to data. Product group A contains subcategories X and Y, gross margin is calculated with a specific formula, the comparison period is always the previous year. These rules guide the language model to make the correct choices.
Real estate data analysis is a good example. In the original data, rental areas were described in text form, for example, "40–50 square meters". The language model could not make comparisons with this type of data. When the fields were split into separate numerical values and the columns were clearly named, the system began producing reliable answers. The mere rearrangement of the data without any model changes significantly improved the results.
What if the answer cannot be found?

When a user asks for data that does not exist, a good system does not invent an answer. It states that the answer was not found and offers the nearest comparable reference point.
This requires more from metadata than just concept definitions. The system needs to know which things are comparable with each other. For example: if there is no data for a certain city district, which nearby area is comparable? If there are insufficient observations for products of a certain size, what broader category is meaningful?
This is practically the point where "talking with data" becomes genuinely useful. Merely retrieving answers is information retrieval. When the system can navigate missing data and suggest alternatives, a dialogue is created.
AI and large language models have changed how we work with metadata
Defining metadata is no longer just a philosophical discussion and manual, seemingly endless work where the benefits are difficult to assess. In this, as in other matters related to operational development, it is good to choose where to start, experiment, learn, and quickly achieve visible benefits.
1. Create the first version using a language model. Existing reports, data models, documentation, business process maps, and data warehouse metadata allow for a quick start. This is actually what has been most accelerated by AI. The first usable version typically emerges in weeks, not months.
2. Choose where to start. It is not worth trying to cover everything at once. Start with the most important use cases and build the metadata using them. A good starting point is to think about the 5–10 questions that the business asks the data most often.
3. Update metadata based on use. When metadata is used by language models, we genuinely see where it does not work correctly. The first version is never complete. Users' real questions reveal shortcomings faster than any pre-planning. Correct errors, add missing descriptions, and refine business rules as you go.
The most important thing is to understand that the first version is created quickly, but production-level reliability requires continuous improvement across the different layers of metadata. That is not a problem; it is the normal way to build solutions of this type.







.svg)


.png)
.png)



.svg)