

.png)
.svg)
Olemme kehittäneet sovelluksen, jolta voi kysyä miten tuoteryhmän kate on kehittynyt viimeisen 12 kuukauden aikana ja vastaukseksi saa tarkan kuvauksen kehityksestä sekä muutoksen vaikuttaneet syyt. Tämän tyyppiset ratkaisut ovat jo arkipäivää, mutta mitä tällaisen sovelluksen tuotannollistaminen isossa yrityksessä käytännössä tarkoittaa?
Tuskin missään enää väitellään otetaanko yrityksessä tekoäly tai kielimallit käyttöön. Isompi kysymys on onko organisaation data riittävän hyvässä kunnossa, saatavilla ja metadata siinä kunnossa, että tekoälystä saadaan oikeasti hyötyä.

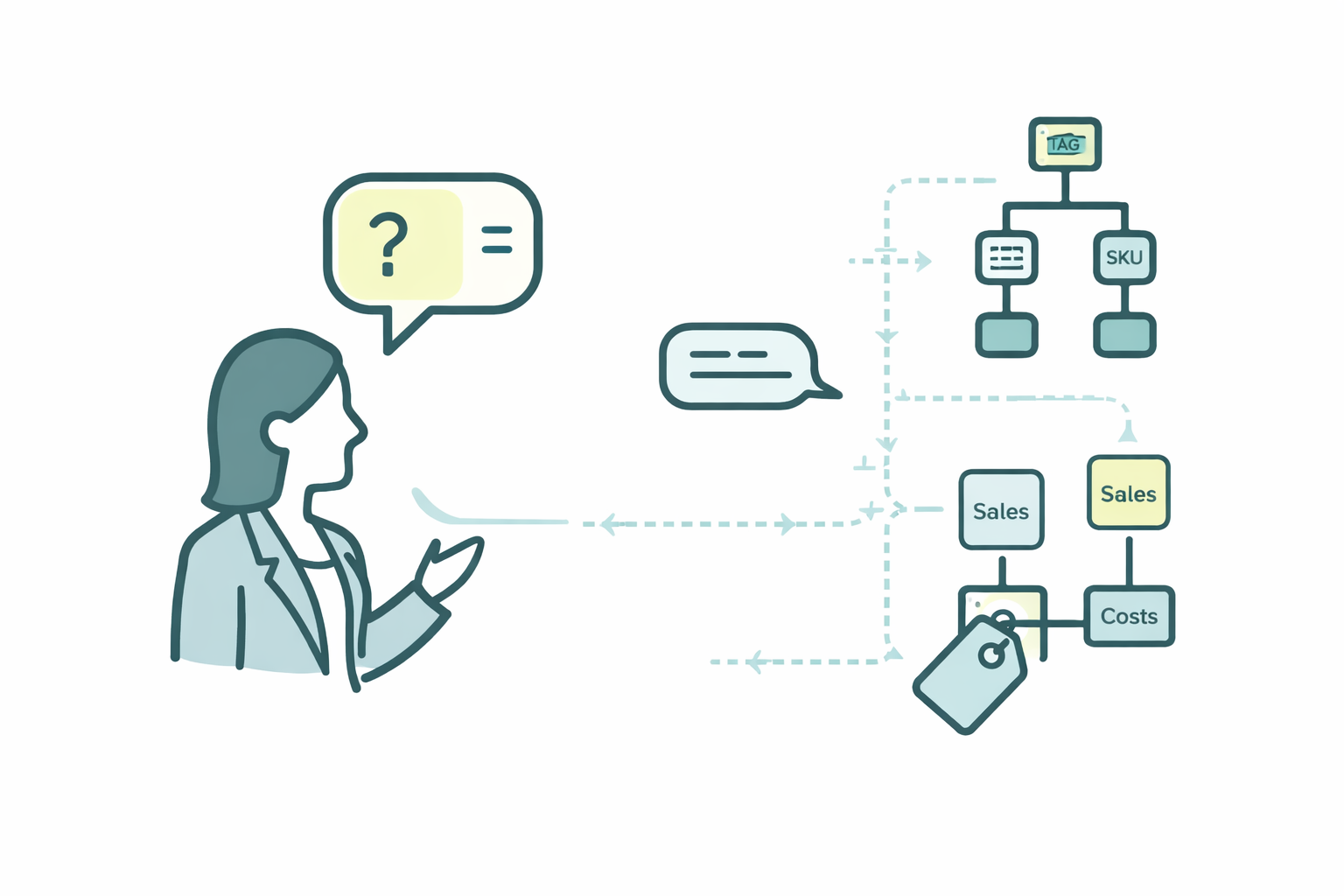
Tarkoitukseni on avata omien kokemusteni pohjalta miten lähestyä metadataa, ei niinkään filosofisena harjoituksena vaan käytännöllisenä asiana. Tavoitteenahan on päästä keskustelemaan datan kanssa.
Mitä on hyvä tietää ennen keskustelua?
Metadata on tietoa tiedosta. Kielimalli täyttää aukot tiedoissaan ja täytetty aukko kuulostaa luotettavalta. Kielimalli ei kerro arvaavansa. Jos datakenttä on nimetty marg_adj_3 eikä sen merkitystä ole dokumentoitu, kielimalli yrittää arvata muusta kontekstista. Suuressa ympäristössä tämä tapa johtaa vastauksiin, jotka kuulostavat oikealta, mutta eivät välttämättä ole sitä.
Hyvä sovellusarkkitehtuuri voi lieventää tätä ongelmaa esimerkiksi pakottamalla mallin kertomaan, kun se ei tiedä vastausta. Mutta arkkitehtuuri ei yksin riitä. Luotettava metadata ja oikea arkkitehtuuri yhdessä tekevät vastauksesta luotettavan.
Toinen käytännön ongelma on se, että sama asia tarkoittaa eri asioita eri puolilla organisaatiota. Teollisuusyrityksen kontekstissa kate voi tarkoittaa myyntikatetta, käyttökatetta tai katetuottoa riippuen siitä, keneltä kysytään. Ilman yhteistä käsitteistöä sovellus ei osaa tarjota kielimallille oikeaa kontekstia, jolloin vastaus voi perustua väärään dataan.
Käsitteiden määrittelyllä ja dokumentoinnilla kielimalli voi yhdistää käyttäjän luonnollisen kielen oikeaan dataan ja perustella vastauksensa liiketoiminnan omalla kielellä. Sitten datan kanssa puhumisesta tulee mielekästä.
Mitä metadatan pitäisi sisältää?
Käsitemallista on hyvä aloittaa. Niin on tehty ennenkin. Selvitetään mitkä ovat keskeiset käsitteet ja miten niillä kuvataan yrityksen toimintaa. Asiakas, tuote, toimittaja. Mitä liiketoimintakäsitteitä organisaatiossa on? Tuoteryhmä, kate, myyntiorganisaatio, myyntikanava. Nämä muodostavat business glossaryn ytimen. Kielimallit on oikein oiva työskentelykaveri tässä työssä.
Seuraava askel on käsitteiden väliset suhteet. Tuoteryhmä kuuluu tuotehierarkiaan, kate lasketaan myynneistä ja kustannuksista, kustannuksilla on oma luokittelunsa. Tuotteeseen liittyy nimike ja erilaisia ominaisuuksia. Ontologia tekee käsitteiden väliset suhteet konkreettisiksi, jolloin kielimalli ymmärtää tiedon rakenteen eikä sen tarvitse päätellä yksittäisten kenttien nimistä tai kontekstista.
Kun semanttinen malli on olemassa, sovellus osaa hakea oikeat datan määrittelyt ja tuoda ne kielimallin käyttöön.
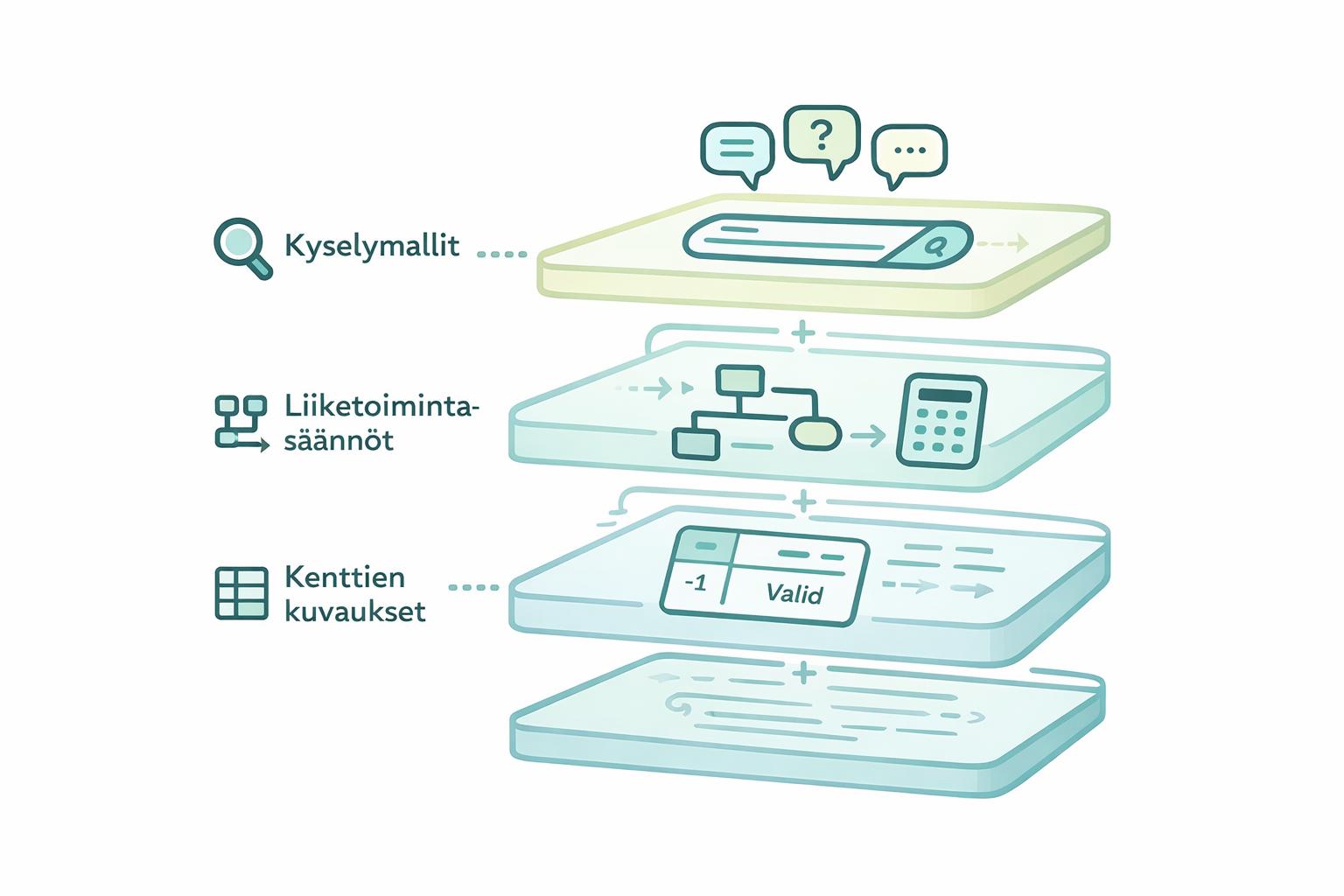
Käytännössä semanttinen malli ei kuitenkaan ole yksittäinen tiedosto tai dokumentti. Se koostuu useammasta kerroksesta, joilla on eri tehtävät:
Sarakkeiden ja kenttien kuvaukset kertovat kielimallille mitä kukin datakenttä tarkoittaa ja mitkä arvot ovat sallittuja. Esimerkiksi kiinteistödatassa arvo -1 voi tarkoittaa "kaikki kategoriat yhteensä". Ilman tätä tietoa kielimalli saattaa käsitellä sitä virheellisenä lukuna.
Kyselymallit yhdistävät tyypilliset kysymykset oikeisiin hakutapoihin. Kun käyttäjä kysyy "miten vuokrat ovat kehittyneet", järjestelmä tunnistaa tämän aikasarjakyselyksi ja osaa hakea oikean datan oikealla tavalla.
Liiketoimintasäännöt määrittelevät miten käsitteet suhteutuvat dataan. Tuoteryhmä A sisältää alakategoriat X ja Y, myyntikate lasketaan tietyllä kaavalla, vertailukausi on aina edellinen vuosi. Nämä säännöt ohjaavat kielimallia tekemään oikeat valinnat.
Kiinteistöalan data-analyysi on hyvä esimerkki. Alkuperäisessä datassa vuokra-alueet oli kuvattu tekstimuodossa, esimerkiksi "40–50 neliötä". Kielimalli ei pystynyt tekemään vertailuja tällaisella datalla. Kun kentät pilkottiin erillisiksi numeerisiksi arvoiksi ja sarakkeet nimettiin selkeästi, järjestelmä alkoi tuottaa luotettavia vastauksia. Pelkkä datan uudelleenjärjestely ilman mitään mallimuutoksia paransi tuloksia merkittävästi.
Entä kun vastausta ei löydy?
Kun käyttäjä kysyy dataa, jota ei ole olemassa, hyvä järjestelmä ei keksi vastausta. Se kertoo, ettei vastausta löytynyt, ja tarjoaa lähimmän vertailukohdan.
Tämä vaatii metadatalta enemmän kuin pelkkiä käsitemäärittelyjä. Järjestelmän pitää tietää, mitkä asiat ovat keskenään vertailukelpoisia. Esimerkiksi: jos tietystä kaupunginosasta ei ole dataa, mikä lähialue on vertailukelpoinen? Jos tietyn kokoluokan tuotteista ei ole riittävästi havaintoja, mikä laajempi luokka on mielekäs?
Tämä on käytännössä se kohta, jossa "datan kanssa keskustelu" muuttuu oikeasti hyödylliseksi. Pelkkä vastausten hakeminen on tiedonhakua. Kun järjestelmä osaa navigoida puuttuvaa dataa ja ehdottaa vaihtoehtoja, syntyy dialogi.

Tekoäly ja kielimallit ovat muuttaneet metadatan kanssa työskentelyn
Metadatan määrittäminen ei ole enää pelkkää filosofista keskustelua ja manuaalista ikuisuudelta tuntuvaa työtä, jossa hyödyt on vaikeasti arvioitavissa. Tässä, niin kuin muissakin toiminnan kehittämiseen asioissa, on kuitenkin hyvä valita mistä aloittaa, kokeilla, oppia ja saada näkyvää hyötyä aikaan nopeasti.
1. Tee kielimallilla ensimmäinen versio. Olemassa olevilla raporteilla, tietomalleilla, dokumentaatiolla, liiketoimintaprosessikartalla ja tietovaraston metadatalla pääsee nopeasti liikkeelle. Tämä on itse asiassa se mikä on eniten vauhdittunut tekoälyn avulla. Ensimmäinen käyttökelpoinen versio syntyy tyypillisesti viikoissa, ei kuukausissa.
2. Valitse mistä aloitat. Ei kannata yrittää kattaa kaikkea kerralla. Aloita tärkeimmistä käyttötapauksista ja rakenna metadata niiden avulla. Hyvä lähtökohta on miettiä mitkä ovat ne 5–10 kysymystä, joita liiketoiminta kysyy datalta useimmin.
3. Päivitä metadataa käytön perusteella. Kun metadata on kielimallien käytössä, nähdään oikeasti missä se ei toimi oikein. Ensimmäinen versio ei ole koskaan valmis. Käyttäjien oikeat kysymykset paljastavat puutteet nopeammin kuin mikään ennakkosuunnittelu. Korjaa virheet, lisää puuttuvia kuvauksia ja tarkenna liiketoimintasääntöjä sitä mukaa.
Tärkeintä on ymmärtää, että ensimmäinen versio syntyy nopeasti, mutta tuotantotasoinen luotettavuus vaatii jatkuvaa parantamista metadatan eri kerroksissa. Se ei ole ongelma, se on normaali tapa rakentaa tämän tyyppisiä ratkaisuja.
.png)






.svg)


.png)
.png)



.svg)